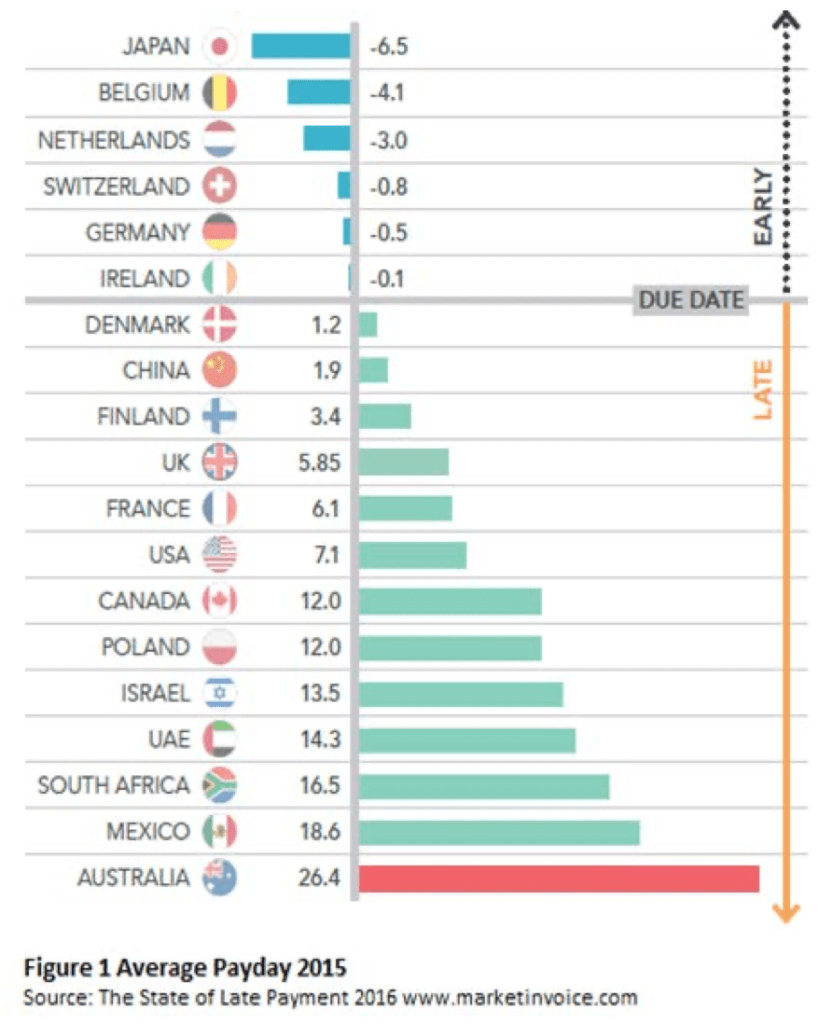
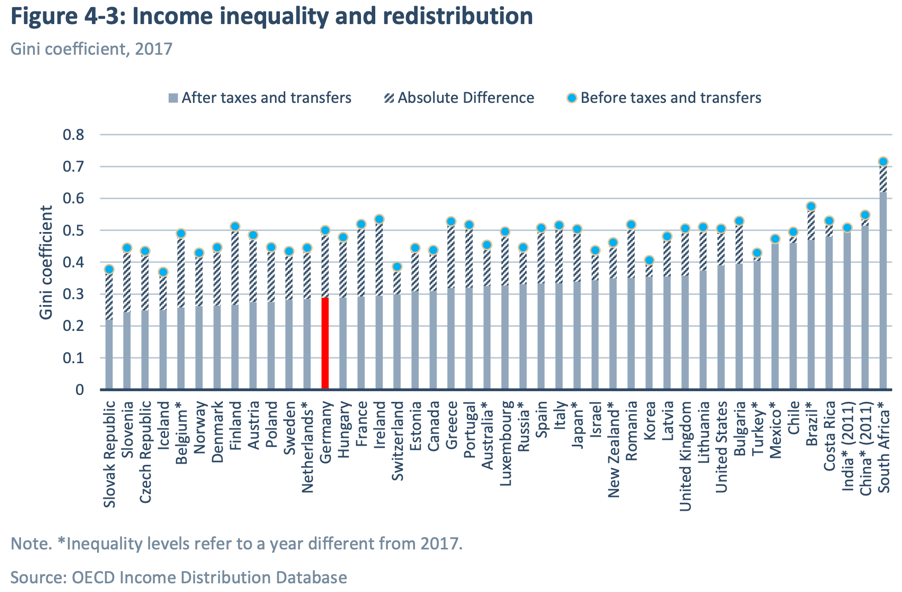
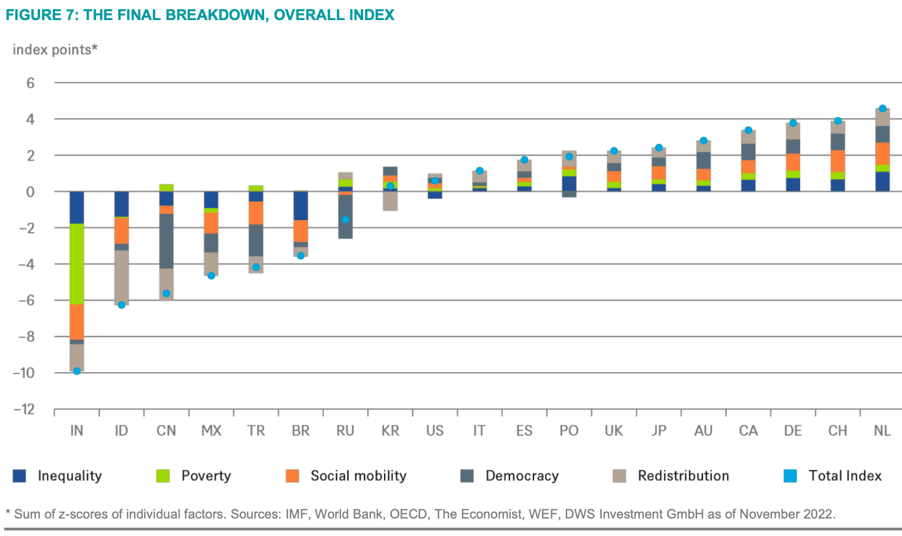
How can we move to a fairer society? First, we must imagine it, argues a new book. And the best starting point for such imagination, it suggests, is the philosophy of John Rawls. The new book is Free and Equal by Daniel Chandler, an economist and philosopher at the London School of Economics.
The book is well worth reading. Its subtitle is the ambitious What would a fair society look like? The ambition is clear, and bracing – though it’s less clear that its relatively conservative prescriptions live up to it.
Chandler sets out a great and concentrated version of his arguments in the first 25 minutes of a discussion hosted by the Royal Society for the encouragement of Arts, Manufactures and Commerce (RSA for short). Fundamentally, his aim is to bring back into active discussion the Rawlsian version of fairness. This vision was based in Rawls’s thought experiment of designing a society when one’s position in it was hidden behind a veil of ignorance. Rawls argued that such a society would be shaped by two basic principles of justice, the first protecting basic liberties and the second coming in two parts, fair equality of opportunity and the difference principle, which allows inequality to the extent it operates to benefit even the least well off in society. Chandler also points to a relatively neglected (frankly, by Rawls as well as others) third principle, the sustainability principle, which focuses on the need for intergenerational fairness.
Needless to say, a Rawlsian fair society would look very different from the one in which we live now. A fair society would require all of us to participate in it equally – with the participation as important as the equality.

Chandler puzzles why Rawls’s thinking has not previously shaped much political thinking, and suggests this is largely down to the shyness and lack of political engagement of the man himself. Maybe, but to me some of Rawls’s work seems to read as a slightly self-satisfied justification of the societal success of the US liberal property-owning democracy of the 1950s and 1960s, in which his thinking was developed – and it seems ignorant of the possibility that some parts of society (notably black people and women) might not have been well-served over that time. Certainly, Rawlsian thinking seemed to be swept aside as Chandler notes by the Reaganite and Thatcherite revolution of the 1980s.
That Thatcherite revolution and its ongoing echoes certainly leave scope for a more radical reading of Rawls, and for its use as a basis for the foundations of a reshaped political approach – and a reshaped society. Whether Free and Equal fully delivers on that is debatable. Many of its prescriptions are ones with much common currency; as Ryan Shorthouse, executive chair of conservative thinktank Bright Blue, indicated in an excellent recent webinar hosted by the Fairness Foundation and KCL’s Policy Institute:
“I thought that at times maybe the policy recommendations, some of them, were a little conventional…sometimes I felt that the policies didn’t necessarily match the radical, lofty vision that Daniel set out to change society”
Chandler is at his most radical in considering political matters. He argues for proportional representation and the replacement of the House of Lords – fairly unsurprising prescriptions for those seeking equal treatment of people in politics. But he also argues for the removal of the excess influence of wealth on politics, by barring larger donations and substituting a voucher system (he likes vouchers!) whereby every individual has a limited sum per year or per electoral cycle to award to the party of their choice. He’s right that the desire of parties to earn people’s vouchers might have the desirable knock-on consequence of reinvigorating political discourse and engagement at the grass-roots.
He makes less radical suggestions on promoting equality of opportunity. These largely revolve around better educational provision throughout the educational lifecycle, and a removal of the advantages enjoyed by fee-paying schools, as well as barriers that arise through the cost of further education. Chandler also argues in favour of positive discrimination to lean against the persistence of racial and gender inequalities.
His radicalism is moderate in his discussion of shared prosperity. He presses for a universal basic income, a concept so much talked about it is sometimes easy to forget how dramatic are the differences that it might bring. He calls for in effect a universal basic inheritance – though at levels that seem a distance away from ‘basic’. He argues that higher taxation, especially on wealth, is likely to be less damaging than sometimes claimed. And he presses for greater workforce democracy, largely in terms of promoting a worker cooperative model and by a general adoption of the German co-determination model (which for no readily apparent reason he insists on calling co-management). According to Shorthouse, such democratising of business structures may be a way to appeal to politicians of both the right and the left.
In a sense though, this focus on democratising business ignores the extent to which public companies are already owned by the workforce, in the form of pension schemes. That ownership is mediated through investment institutions, but as pension schemes and other institutions feel obliged to communicate to individual beneficiaries more effectively, and in particular are more transparent about their actions as stewards of the companies in which they invest, the barriers to individuals’ understanding of their influence as owners are being eroded. Where that may take the societal understanding of capitalism – and the areas of stewardship on which investors focus – remains to be seen.
It is this area of grass-roots and genuinely broad-based engagement in society that is at its core the most radical opportunity which a Rawlsian world offers to us all. Chandler hints at it in various ways, but more work is needed to understand what it might mean and how it might best be awakened.
Colin Bradley, philosopher and legal scholar with links to both Princeton and New York University School of Law, considers the social and collaborative aspects of Rawls’s thinking in an interesting recent essay: “For Rawls, liberalism revolves around two ideals: society as a fair system of cooperation, and people as free, equal, capable of acts of joy, kindness and creativity; and disposed – if not always without reluctance – to cooperate with one another to flourish.”
Sometimes, writes Bradley:
“‘society’ simply feels like something we are ‘caught in’ rather than something we are making and sustaining together, Rawls wrote in Political Liberalism (1993)”
To adapt a phrase Andy Haldane quoted about democracy at the RSA event, we need to act like producers of society, not consumers of it. Certainly, we need not to feel caught by it, but part-creators of it. If we are to make it fair – and also free and equal – we need to work to produce that end, not simply expect it to be presented to us. Rawls, as Chandler points out, provides us with an intellectual framework for considering policy prescriptions to help us in these positive directions. We may need to move beyond conventional solutions to deliver that fairness.
See also: Squid game ‘fairness’
Free and Equal, What would a fair society look like?, Daniel Chandler, 2023
A Theory of Justice, John Rawls, 1971
Justice as Fairness: A Restatement, John Rawls, 2004
What would a fair society look like?, webinar hosted by Royal Society for the encouragement of Arts, Manufactures and Commerce (RSA), April 2023
How to create a fair society: can the left and the right find common ground?, webinar hosted by Fairness Foundation and the Policy Institute at Kings College London, 26 October 2023
Liberalism against capitalism, Colin Bradley, Aeon, 11 August 2023