
Technology will not of itself generate fairness. Merely asserting that the independence and lack of human intervention in a process removes bias isn’t true — indeed it may require human intervention to overturn failures to be fair. After all, fairness requires effort. This is the lesson that ought to be being learned in the world of algorithms, but unfortunately too often the creators and users of algorithms seem to prefer to state that they will be fair without actually carrying out the work effort that will deliver fairness in practice.
No parent of secondary school age children in England needs to be told that algorithms are not inherently fair. The debacle this summer of the supposedly standardised grades for students leaving school, who had lost the opportunity actually to sit their final exams because of Covid-19, brought the potential for technological unfairness fully into view.
The key political decision was that there should not be significant grade inflation arising from the use of teachers’ assessed grades. The way that was operationalised created the unfairness, particularly the view that results awarded should be in line with schools’ historic performance (startlingly, almost 40% of teacher assessed grades were downgraded). The unfairness arose despite regulator Ofqual’s explicit aim being to deliver fairness for students. For example, the regulator required less standardisation of smaller classes than larger ‘cohorts’, because adjustments in smaller classes might appear more arbitrary. But a key consequence of this was that fee-paying private schools (which market themselves in part based on offering more esoteric subjects and smaller class sizes) faced fewer downgrades than free state schools. That looked like unacceptable unfairness to many.
Furthermore, the tying of performance to historic grades anchored exceptional years, or improving schools, to their less successful heritage. Fundamentally in a system that has to be all about what the individual her- or him-self deserves, an automated process for determining performance is always going to create some degree of unfairness at a granular level — especially so when the algorithm directly limited the number of certain grades that could be awarded to a particular school, condemning some individuals to multiple downgrades from those their teachers predicted for them.
The scale and number of these apparent individual unfairnesses in the end led to a government decision to abandon the algorithm and simply revert to those teacher-assessed grades. No doubt there is some unfairness in that, but at least it appears less systematic unfairness.
So even where the aim explicitly is fairness, that is not necessarily what will be delivered if the design of the algorithm is faulty and it is subject to inadequate testing.
The scope for unfairness is much greater in cases where fairness is not the aim being sought. And where that application is to areas as sensitive as law enforcement and incarceration (as it increasingly is) then unfairness creates very fundamental problems.
Take facial recognition, a technology increasingly used particularly at border crossings to identify those who can be allowed into a country and those who should be excluded. In theory perhaps the use of technology should remove bias. In practice, however, the technology is racist.
A remarkable December 2019 study by the US’s National Institute of Standards and Technology of more than 100 leading facial recognition systems, including ones from the most famous names in technology, reveals that even the best facial recognition systems misidentify black people at rates 5-10 times higher than the misidentification of white people. This chart is but one sample of the striking data the analysis reveals:
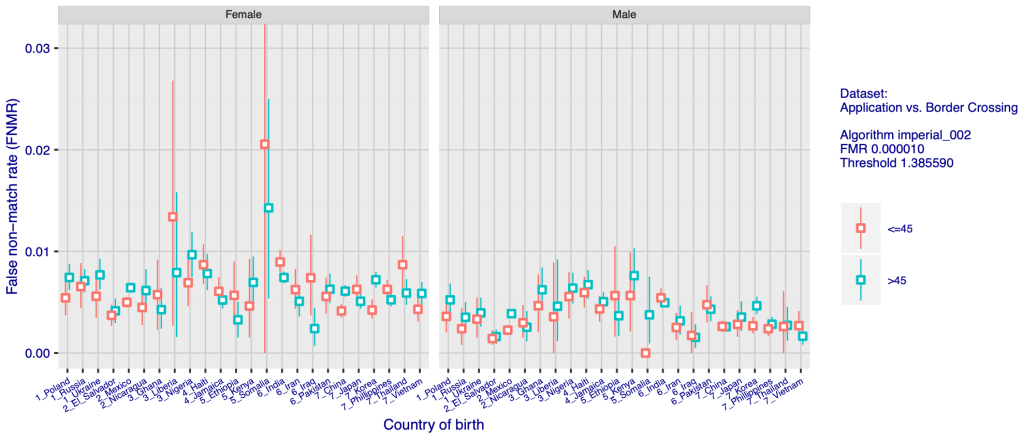
Source: National Institute of Standards and Technology
As is obvious from this chart, not only are the facial recognition systems racist, they are also sexist. They are not as sexist as they are racist, but the algorithms are consistently worse at identifying women correctly. They also happen to be worse at identifying older people and children, getting worse and worse at the increasing extremes of age.
There is a consistent reason for these general errors: the development of the AI has been focused on one demographic, trained on a set of data. In most cases, that has predominantly been adult men from the locality of the developer. There is a strong home bias in the datasets used to develop the algorithms, meaning that there is a contrast between the data from most of the systems with the results from those developed in China: “with a number of algorithms developed in China this effect is reversed, with low false positive rates on East Asian faces”.
This reveals a general challenge about AI. There is a sense in which the creation of algorithms is based on the creators’ existing understanding of the world around them. Given that our world is riddled with unfairness, it is not surprising that unfairness is an outcome of their work — unless they deliver actions that actively work to remove the unfairness.
As Hetan Shah, then Executive Director of the Royal Statistical Society, now CEO of the British Academy (and also vice-chair of the Ada Lovelace Institute and chair of the Friends Provident Foundation), sets out in an excellent brief paper on Algorithmic Accountability:
“Algorithms for the most part are reflecting back the bias in our own world. A large part of ‘bias’ in algorithms comes from the data they are trained upon.”
It therefore follows that we need to lean actively against existing bias and prejudice in order to make algorithms more fair. Among the steps which would assist in this, Shah argues, are enhancing the diversity of the technology workforce, ethics training and a professional code of conduct for all data scientists, and new deliberative bodies to help set standards, and build ethics capacity.
The tech industry is alive to at least some of these issues — or sounds like it is. The language of fairness is used freely in its discussions of its own work. For example, in January 2018 Microsoft published its “ethical principles” for AI, which start with ‘fairness’. In May of that same year, Facebook announced its “commitment to the ethical development and deployment of AI” which includes a tool that it claims can systematically seek out and identify bias in algorithms, called ‘Fairness Flow’. That September saw IBM announce its ‘AI Fairness 360’, which is similarly designed to “check for unwanted bias”. The word appears prominently among the stated intents of Alphabet (Google) and Amazon.
The firms have also freely sponsored academic and other programmes supporting the development of fairness in AI, such as the Algorithmic Fairness and Opacity Group at Berkeley, that same University’s Center for Technology, Society & Policy (which has a project on Just Algorithms: Fairness, Transparency, and Justice), and the US National Science Foundation Program on Fairness in Artificial Intelligence.
Rodrigo Ochigame, who has worked within at least one of these organisations, is cynical about this: “Today’s champions of ‘algorithmic fairness’, sometimes sponsored by Silicon Valley firms, tend to frame discrimination and injustice as reducible to the stated distinction between the optimization of utility and other mathematical criteria”. His charming short article on the history of algorithmic fairness travels far — from 17th century English real property law, through 19th century US insurance contracts — and makes it clear that delivering fairness is not, and never has been, as simple as the champions of technology want it to seem.
In an earlier, excoriating article, Ochigame argues that the current efforts are little more than active lobbying for limited regulation. “Silicon Valley’s vigorous promotion of ‘ethical AI’ has constituted a strategic lobbying effort, one that has enrolled academia to legitimize itself,” he argues. This lobbying effort “was aligned strategically with a Silicon Valley effort seeking to avoid legally enforceable restrictions of controversial technologies”.
Certainly, despite all the language of fairness, the example of the facial recognition algorithms suggests that there is still a long way to go to deliver fairness in practice. Ochigame identifies a number of other uses of algorithms in law enforcement and the criminal justice system that appear in practice to be delivering clear unfairness.
The US’s Brookings Institute shares these concerns, highlighting a series of biased outcomes from algorithms, including gender bias in an Amazon recruitment algorithm, and bias in the online advertisements shown to online searchers, reinforcing existing prejudice and closing the door to difference. Just as with the facial recognition algorithms, the approach of building from what already exists or is near at hand leads to algorithms “replicating and even amplifying human biases, particularly those affecting protected groups”. This tendency, Brookings argues, is particularly concerning where technology is used in the criminal justice environment, to identify ‘potential’ criminals or sites of crime, or to help determine sentence lengths or the availability of bail. The solution, they believe, is not a technology one:
“companies and other operators of algorithms must be aware that there is no simple metric to measure fairness that a software engineer can apply, especially in the design of algorithms and the determination of the appropriate trade-offs between accuracy and fairness. Fairness is a human, not a mathematical, determination, grounded in shared ethical beliefs. Thus, algorithmic decisions that may have a serious consequence for people will require human involvement.”
Indeed, it seems as though algorithms risk becoming in some way a technological version of the sus law, the 1970s use of long-standing laws enabling the UK police to stop and question any individual suspected of intent to commit an arrestable offence. The sus law became a vehicle for blatant prejudice and harassment of ethnic minorities, and was repealed in 1981 following a series of race riots. The crudeness of social profiling by the police in the 1970s — even senior officers claiming that disproportionate targeting of black people was justified because they were over-represented among robbery and violence offenders — is reflected in much of the algorithmic modelling now being applied. Using technology does not make the work more fair or justifiable. It is just prejudice in another, perhaps less accountable, form.
The use of algorithms in the business arena has also been found to introduce unfairness. A recent study considers the German retail petrol (gasoline) market, which started to adopt algorithmic pricing in a significant way in 2017. Essentially, this study provides evidence that such pricing algorithms can drive anti-competitive behaviour: adoption of algorithms increases margins by 9% on average, even though non-monopoly markets show no margin enhancement at all. Looking just at duopoly markets, the researchers conclude: “we find that market-level margins do not change when only one of the two stations adopts, but increase by 28% in markets where both do.” The consequence is “a significant effect on competition”. It should probably come as no surprise that pricing algorithms push prices up; the question is whether this can be justified or whether it just amounts to a technological cover placed over the gouging of customers.
So fairness continues to be a victim in practice of the use of at least some algorithms, despite the apparent efforts by the technology giants to promote and assure the delivery of fairness. And rather than coming from the organisations they fund, in practice the best outlines of what is really necessary to deliver fairness in artificial intelligence — at least that I have been able to identify — come from other sources.
Of course the EU’s High-Level Expert Group on AI includes individuals from many of the leading technology firms, but the group is wider than that. In April 2019, it presented its Ethics Guidelines for Trustworthy Artificial Intelligence. Among the seven key requirements that AI systems need to meet to be deemed trustworthy, is the fifth, Diversity, non-discrimination and fairness. This states: “Unfair bias must be avoided, as it could could have multiple negative implications, from the marginalization of vulnerable groups, to the exacerbation of prejudice and discrimination. Fostering diversity, AI systems should be accessible to all, regardless of any disability, and involve relevant stakeholders throughout their entire life circle.”
In July 2020, the High-Level Expert Group took this work further and presented its final Assessment List for Trustworthy Artificial Intelligence. This provides questions for assessing whether AI delivers on the trustworthiness measure that the Group set. Among the questions under Diversity, non-discrimination and fairness are:
Is your definition of fairness commonly used and implemented in any phase of the process of setting up the AI system?
- Did you consider other definitions of fairness before choosing this one?
- Did you consult with the impacted communities about the correct definition of fairness, i.e. representatives of elderly persons or persons with disabilities?
- Did you ensure a quantitative analysis or metrics to measure and test the applied definition of fairness?
- Did you establish mechanisms to ensure fairness in your AI system?
This looks very similar to the simple model that Hetan Shah suggests for reducing and perhaps removing bias: (1) pilot to check for bias in multiple ways, with different datasets; (2) offer transparency to enable external scrutiny; (3) monitor outcomes for differential impacts; (4) provide a right to challenge and seek redress; and (5) enable enhancement through good governance (e.g. through independent oversight). In the context he is considering, of public data being used in algorithms by private companies, he also suggests (6) use of negotiating strength by the public sector as monopoly owner of data which private sector rivals are competing for.
Brookings reaches similar conclusions, proposing the idea of ‘Algorithmic Hygiene’, “which identifies some specific causes of biases and employs best practices to identify and mitigate them”. It is unsurprising therefore that one of their key recommendations for enhancing fairness is to: “Increase human involvement in the design and monitoring of algorithms”.
As an aside, this danger that arises from assuming our starting point needs to be the world as it is and as we understand it is consistent with other concerns — as Brookings notes, the biases in search arise from similar errors. I worry about algorithms constraining our horizons and feeding confirmation biases. In particular, I worry about the role of algorithms in defining search and so much of our online lives, of cookies constraining what we see. This removes the joy of serendipity and happenstance. A friend complains that using any search engine other than his usual one of choice (you can guess which) means that he sees all sorts of untargeted, irrelevant material. Perhaps his approach is more efficient by fractions of seconds, but inefficiency occasionally has its benefits and I suspect we lose much by seeking to avoid it — or by handing the power of happenstance over to a machine which tends to want to confirm our certainties rather than enable us to happen upon challenge and difference. The algorithm is the echo chamber.
Algorithms, like any human technology, are neither fair nor unfair. They are not automatically fair, as their IT proponents would like us to believe; nor are they automatically unfair as many campaigners seem ready to argue. Like any human technology, they reflect the prejudices and understandings of their creators and the society in which they are created. We live in an unfair world and so most technology, if it does not actively lean against unfairness, will be unfair. There needs to be much more work to ensure that algorithms operate fairly — merely being technology does not deliver that, without much, much more. A technology industry that fails fully to engage with this challenge will not build the necessary trust and will see confidence in algorithmic technology erode. Current unfairnesses suggest that the industry has much more work to do.
Small corrections made October 18 2022 following input from a member of Data Ethics Club. With thanks.
See also: Learning from the Stochastic Parrots
Awarding GCSE, AS, A level, advanced extension awards and extended project qualifications in summer 2020: interim report, Ofqual, August 2020
Face Recognition Vendor Test (FRVT) Part 3: Demographic Effects, Patrick Grother, Mei Ngan, Kayee Hanaoka, National Institute of Standards and Technology, December 2019
Algorithmic accountability, Hetan Shah, Philosophical Transactions, Royal Society, A 376: 20170362, April 2018
The Long History of Algorithmic Fairness, Rodrigo Ochigame, Phenomenal World, January 30 2020
The Invention of ‘Ethical AI’ – How Big Tech Manipulates Academia to Avoid Regulation, Rodrigo Ochigame, The Intercept, December 20 2019
Algorithmic bias detection and mitigation: Best practices and policies to reduce consumer harms, Nicol Turner Lee, Paul Resnick, and Genie Barton, Brookings Institute, May 22, 2019
Algorithmic Pricing and Competition: Empirical Evidence from the German Retail Gasoline Market, Stephanie Assad, Robert Clark, Daniel Ershov, Lei Xu, CESifo Working Paper No. 8521, August 2020
Ethics Guidelines for Trustworthy AI, High-Level Expert Group on AI, European Commission, April 2019
Assessment List for Trustworthy Artificial Intelligence, High-Level Expert Group on AI, European Commission, July 2020
